No computing cluster? No problem, python’s multiprocessing library makes it easy to melt your CPU by parallelizing numerical integration. Here’s an example.
Suppose we want to reproduce this graph:
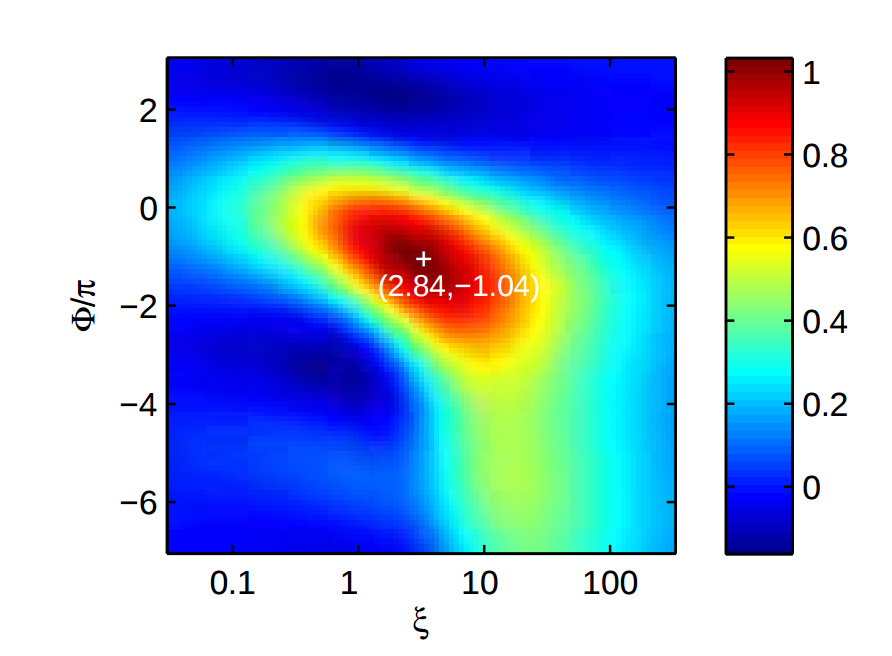
It is plotting the spatial mode overlap between the pump and idler beams of an SPDC process defined by the aggregate focus (xi) and the phase matching between the two beams (phi), which is:
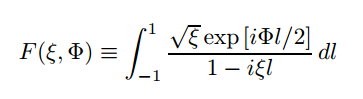
If it weren’t for that nasty integration variable in the denominator, we could use SymPy to find the exact analytical solution, then substitute our range of phi and xi’s, easy-peasy. Instead, we have to use numerical integration. Luckily scipy has an already-optimized integration module, so you don’t need to go digging out your undergraduate scientific computing assignments.
The code to run our range of values through numerical integration could look like:
from numpy import sqrt, exp, arange, pi
from scipy.integrate import quad
def integrate(args):
phi = args[0]
xi = args[1]
return quad(lambda l: sqrt(xi)*exp(1j*phi*l/2.0)/(1.0-1j*xi*l), -1.0, 1.0)
if __name__ == "__main__":
num_points = 100.0
phase_mismatches = arange(-7.0, 3.0, 10.0/num_points)
aggregate_focus_logs = arange(-1.5, 2.5, 4.0/num_points)
parameters = []
for phase_mismatch in phase_mismatches:
phi = float(phase_mismatch*pi)
for aggregate_focus_log in aggregate_focus_logs:
xi = float(10.0**aggregate_focus_log)
parameters.append([phi, xi])
results = []
for parameter in parameters:
results.append(integrate(parameter))
My laptop has a quad-core AMD A10-7300: not a chip for serious computations, but acceptable for most of what I do. With python 2.7, this code takes an average of 2m21 seconds to complete (on python 3.4 it takes 2m31s). Although not a lot of time, it’s enough so that my focus is broken and my mind will drift to other things, which is bad for flow.
Because the integration of each of these points is independent, this task is an excellent candidate for parallelization. Python has several libraries for parallelization, but since I’m running this example on my laptop and not a distributed or cluster computer, using the standard library multiprocessing is the easiest. This requires only a slight modification of the code; instead of using a for loop to iterate over the parameters, we simply need to create a process pool and map the parameters onto the result:
p = Pool(4)
results_pooled = p.map(integrate, parameters)
To make sure that the process of parallelization did not change the result somehow, we can check the serialized and parallelized results:
for i in range(len(results)):
assert results_pooled[i] == results[i]
For this example, at least, the results are the same. The parallelized computation takes an average of 47.5 seconds on both python 2.7 and python 3.4. Long enough to be frustrating, but not long enough to get distracted.
This is what the CPU usage looks like when the calculations are run one after the other:
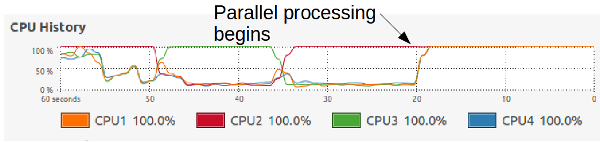
During serial execution, only one CPU is used to 100%; during parallel computation, all 4 CPUs are occupied at 100%. No heat alarms yet :p.
Troubleshooting
Once executed in a pool, error messages become less helpful. For example, you may get something like this:
Traceback (most recent call last):
File "~/multi_processing_example.py", line 30, in <module>
results = p.map(integrate, factors)
File "/usr/lib/python2.7/multiprocessing/pool.py", line 251, in map
return self.map_async(func, iterable, chunksize).get()
File "/usr/lib/python2.7/multiprocessing/pool.py", line 558, in get
raise self._value
multiprocessing.pool.MaybeEncodingError: Error sending result: 'error('Supplied function does not return a valid float.',)'. Reason: 'PicklingError("Can't pickle <class 'quadpack.error'>: import of module quadpack failed",)'
It seems like the scipy integration module hit an error, but the worker process was unable to pack it into a pickle to send back to the main process. An easy way to troubleshoot this is by sending only the first parameter to the function outside of the pool. There we can see the error message of:
Traceback (most recent call last):
File "multi_processing_example.py", line 33, in <module>
results.append(integrate(factor))
File "multi_processing_example.py", line 15, in integrate
result = quad(lambda l: sqrt(xi)*exp(1j*phi*l/2.0)/(1.0-1j*xi*l), -1.0, 1.0)
File "/usr/local/lib/python2.7/dist-packages/scipy/integrate/quadpack.py", line 315, in quad
points)
File "/usr/local/lib/python2.7/dist-packages/scipy/integrate/quadpack.py", line 380, in _quad
return _quadpack._qagse(func,a,b,args,full_output,epsabs,epsrel,limit)
quadpack.error: Supplied function does not return a valid float.
Which occured because we gave one parameter as a non-float.
The multiprocessing library is capable of more complex parallel computations, but often a simple worker pool is sufficient to get a lot of improvement.