The common way to make modifications to sewing patterns is to trace out the cut lines on tracing paper, then cut and tape the pieces of paper together to form a new shape to cut out of fabric. However, as a software developer, every problem is a programming one, so in this post I’m going to show my code for extracting the cut lines from sewing patterns as SVGs, so that you can manipulate them in Inkscape.
The pattern I’m going to use in this demo is the Cheyenne Tunic by Hey June which I recommend purchasing. I use the pdfrw library for reading in the pattern, and investigating a pdf using this library can really help your understanding of the format.
Extracting data from PDFs is quite challenging. If you’re unfamiliar with PDFs, I recommend the O’Reilly book Developing with PDF.
Getting the Right Size
Most sewing patterns store the cut lines for different sizes in original content groups (known as layers in most PDF readers). This allows you to turn off the sizes you don’t want before printing.
I set up a command argument parser to define the filename of the PDF and get the size to extract.
parser = argparse.ArgumentParser(
description='Generate new pattern pieces from existing patterns')
parser.add_argument('--filename', type=str, help='The filename of the pdf pattern.')
parser.add_argument('--size', type=str, help="The size of the pattern to analyze.")
The content groups are defined both in the PDF document’s root, and on each page. The group keys for the content groups are defined under /Resources -> /Properties.
args = parser.parse_args()
x = PdfReader(args.filename, decompress=True)
name = '(' + args.size + ')'
shapes = []
paths = []
for page_num, page in enumerate(x.pages):
if '/Resources' not in page:
continue
if '/Properties' not in page['/Resources']:
continue
oc_keyname = [key for key in page['/Resources']['/Properties']
if page['/Resources']['/Properties'][key]['/Name'] == name]
If there no original content groups matching the size we want, skip to the next page:
if len(oc_keyname) == 0:
continue
Another thing to extract out of the /Resources are the graphics states. If you want a faithful color representation of the graphics when converting PDF to SVG, you need these values. However, since these rules are a bit tricky, and I only care about the shapes, I am not doing anything meaningful with this information at the moment:
gstates = {}
if '/ExtGState' in page['/Resources']:
gstates = page['/Resources']['/ExtGState']
The paths themselves will be in the page’s content stream. You want to start reading at the group key name, and then end at the end of that block, which is typically indicated by the EMC keyword:
lines = page.Contents.stream.split('\n')
start_index = [i for i, l in enumerate(lines) if l.find(oc_keyname) >= 0][0]
end_index = \
[i for i, l in enumerate(lines) if l.find('EMC') >= 0 and i > start_index][0]
shape = "\n".join(lines[start_index:end_index])
PostScript Graphics to SVG
PDF graphics use a format similar to SVG for expressing shapes and paths, but uses a PostScript state machine for updating stylistic elements (like fill and stroke color) and for appending to paths. The instructions are written in reverse Polish notation, where the q operation pushes values onto the state machine and Q pops off the stack. I wrote a PostScript interpreter that goes over the instructions line by line, and adds shapes to a svgwrite Drawing. It’s by no means complete, but it’s good enough for my purposes. Some operators, like n, define clipping paths so that the cut lines render within the page window, and I ignore these.
def parse_shape(shape, i, gstates):
# see https://www.adobe.com/content/dam/acom/en/devnet/acrobat/pdfs/PDF32000_2008.pdf
output_filename = "page%s.svg" % i
dwg = Drawing(output_filename, profile='tiny')
fill = "none"
stroke = rgb(0, 0, 0)
stroke_width = 4
transform = (1, 0, 0, 1, 0, 0)
shapes_stack = []
d = ""
paths = []
for line in shape.split("\n"):
line = line.strip()
parts = line.split(" ")
nums = []
for part in parts:
try:
nums.append(float(part))
except ValueError:
pass
operation = parts[-1]
if operation == 'BDC':
continue
elif operation == 'q':
# q - start stack
continue
elif operation == 're':
# rectangle
vals = {'insert': (nums[0], nums[1]), 'size': (nums[2], nums[3])}
if fill:
vals['fill'] = fill
if stroke:
vals['stroke'] = stroke
shapes_stack.append(dwg.rect(**vals))
elif operation == 'n':
# - clipping path
continue
elif operation == 'RG':
# set stroke color
stroke = rgb(*nums[0:3])
elif operation == 'J':
# not sure how to implement cap styles
continue
elif operation == 'cm':
# current transformation matrix
transform = nums[0:6]
elif operation == 'F' or operation == 'f':
# fill
fill = rgb(*nums[0:3])
elif operation == 'm':
# move to
d += "M " + format_pointstr(parts[0:2])
elif operation == 'c':
# curve
d += " C " + format_pointstr(parts[0:6])
elif operation == 'v':
# append to bezier curve
d += " S " + format_pointstr(parts[0:4])
elif operation == 'y':
d += " C " + format_pointstr(parts[0:4])+" "+format_pointstr(parts[2:4])
elif operation == 'l':
# line to
d += " L " + format_pointstr(parts[0:2])
elif operation == 'h':
# make sure it's a closed path
continue
elif operation == 'S':
# stroke to 4-unit width
continue
elif operation == 'Q':
# end stack (draw)
# apply transformation...
for shape in shapes_stack:
dwg.add(shape)
if len(d) > 0:
paths.append(d + " Z")
d = " ".join([transform_str(p, transform) for p in d.split(" ")])
vals = {'d': d}
vals['stroke-width'] = stroke_width
if fill:
vals['fill'] = fill
if stroke:
vals['stroke'] = stroke
dwg.add(dwg.path(**vals))
d = ''
shapes_stack = []
elif operation == 'gs':
key = parts[0]
if key not in gstates:
print("could not find state %s in dictionary")
state = gstates[key]
# color blending not yet implemented
pass
elif operation == 'w':
stroke_width = nums[0]
else:
print("not sure what to do with %s %s" % (operation, line))
dwg.save()
return paths
PDF uses the same format as SVG for expressing transformations. Here’s my code for applying these transformations, which is copied from my fork of svgpathtools
def transform_point(point, matrix=(1, 0, 0, 1, 0, 0), format="float", relative=False):
a, b, c, d, e, f = matrix
if isinstance(point, list):
x, y = point
else:
point_parts = point.split(',')
if len(point_parts) >= 2:
x, y = [float(x) for x in point_parts]
else:
# probably got a letter describing the point, i.e., m or z
return point
# if the transform is relative, don't apply the translation
if relative:
x, y = a * x + c * y, b * x + d * y
else:
x, y = a * x + c * y + e, b * x + d * y + f
if format == "float":
return x, y
else:
return "%s%s%s" % (x, point_separator, y)
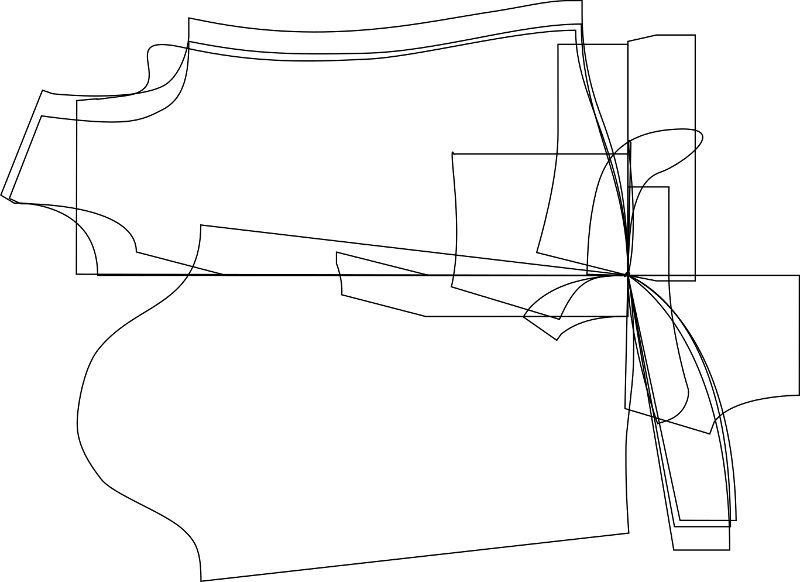
Since the same cut lines are spread accross multiple pages, I want to eliminate duplicate cut lines, which I can do using set, since the shapes are all path strings:
paths = sorted(list(set(paths)))
Here’s all the unique cut lines for the XS shape:
Now that I have the cut lines in SVG format, I can programmatically manipulate them and then print them out again, but that’s a post for another day.